SGI-Bench
Probing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows
10 Disciplines
1000+ Samples
5 Task Families
Agentic Evaluation
Probing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows
Scientific General Intelligence (SGI) is defined as an AI system that can autonomously navigate the full, iterative cycle of scientific inquiry — Deliberation, Conception, Action, and Perception — with the versatility and proficiency of a human scientist.
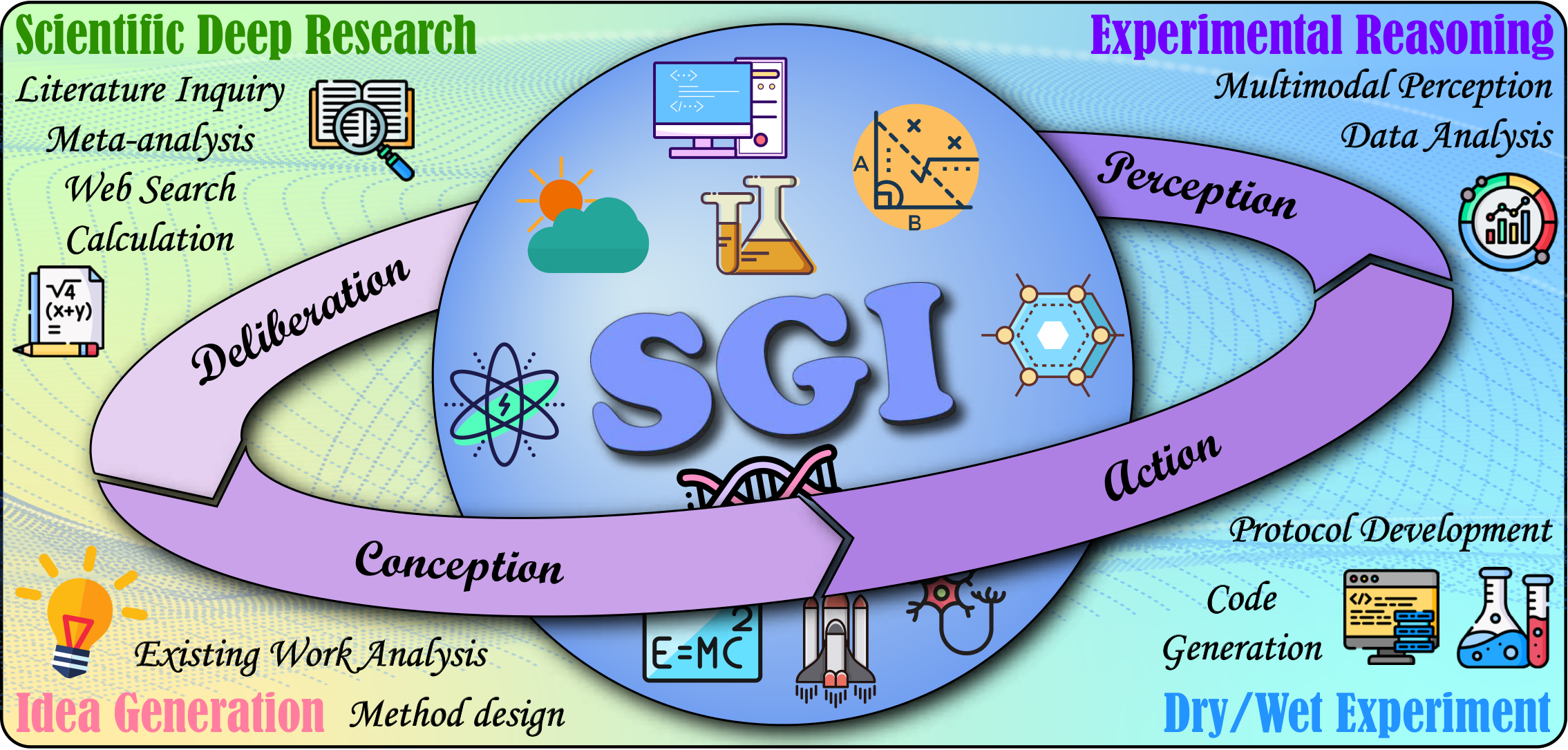

SGI Framework: Iterative cycle of scientific inquiry.
Multi-hop retrieval and meta-analysis style quantitative synthesis across scientific literature.
Structured idea generation and multi-dimensional comparative evaluation of scientific hypotheses.
Scientific code generation (dry) and laboratory protocol development (wet) for real experiments.
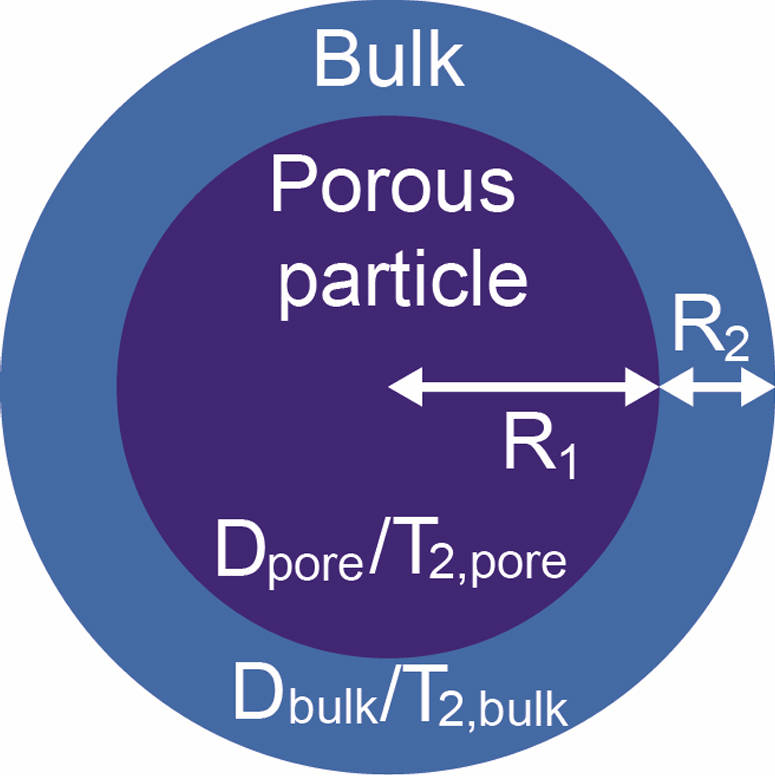
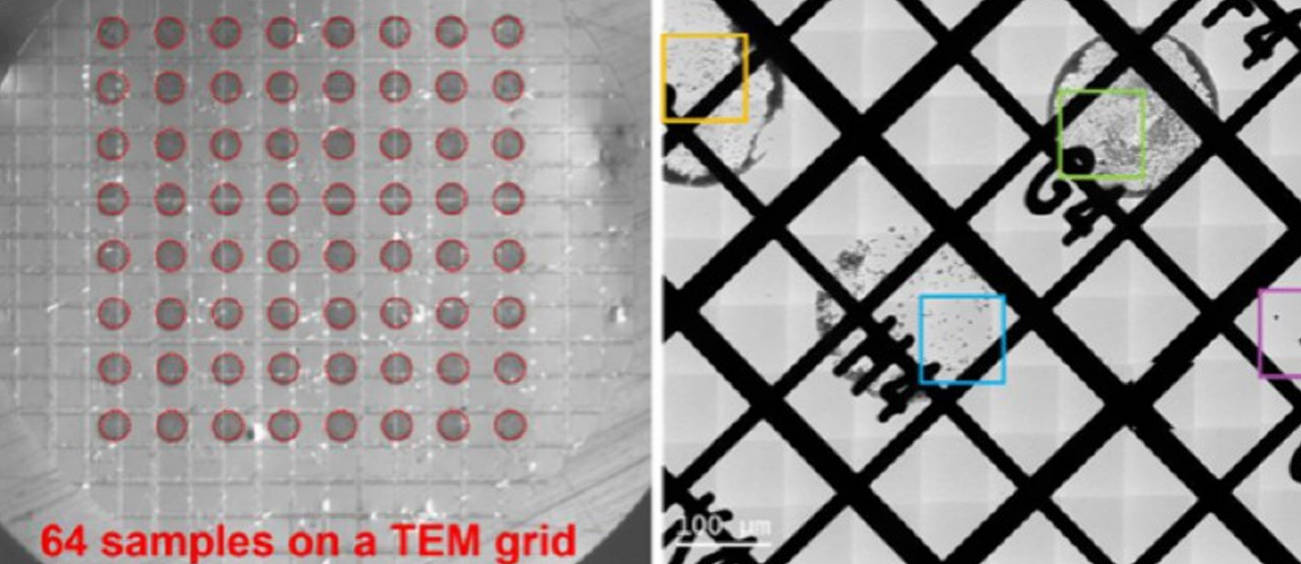
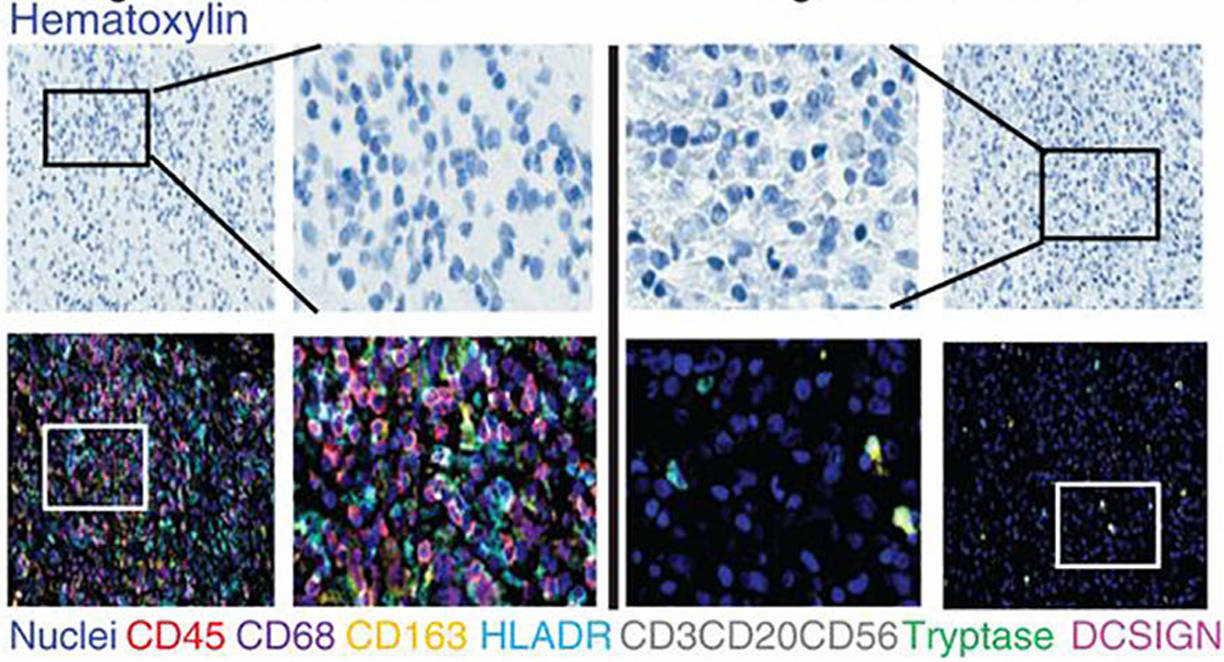
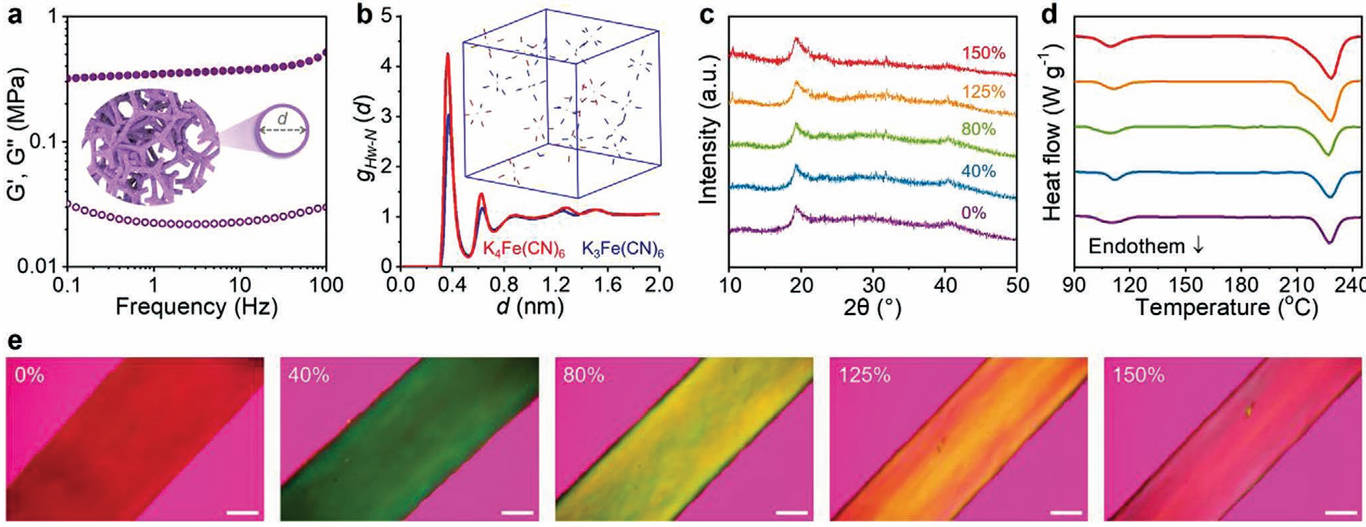
Multimodal reasoning over process, observation, simulation, experiment, and visualization images.
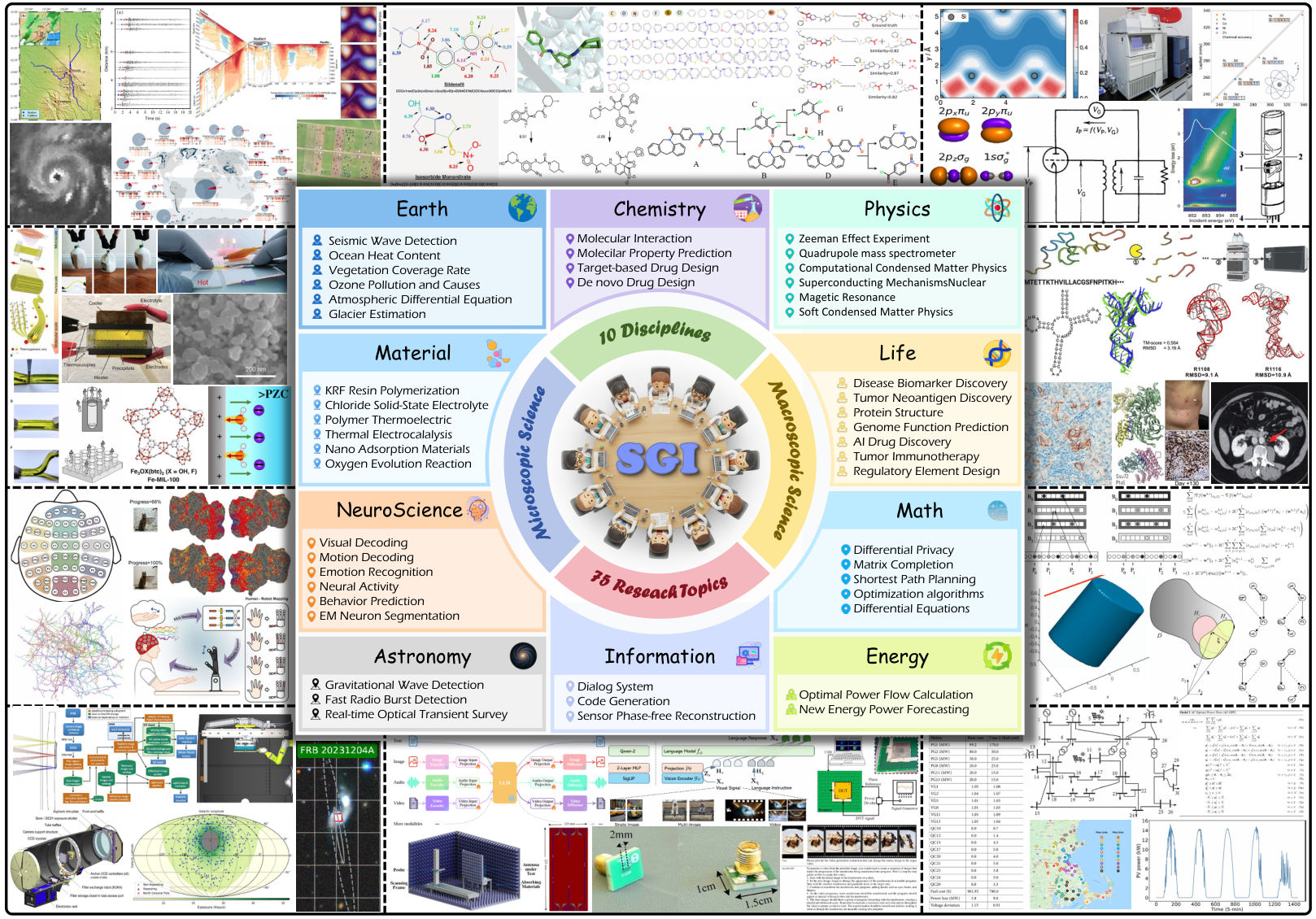
Expert-curated texts/images across 10 domains from Science's 125 Big Questions.
100+ Master's and PhD holders; continuous expert review for scientific value.
Rule-based validation, model checks, expert QA for executability and unique answers.
Remove samples solvable by >50% strong LLMs to maintain high challenge.
SGI-Bench data is scientist-aligned and high-fidelity: an expert-sourced corpus spanning 10 disciplines (inspired by Science's 125 Big Questions), questions constructed by 100+ Master's and PhD holders with continuous scientist-in-the-loop review, multi-stage cleaning to ensure executability, and difficulty filtering that removes items solved by >50% strong LLMs.
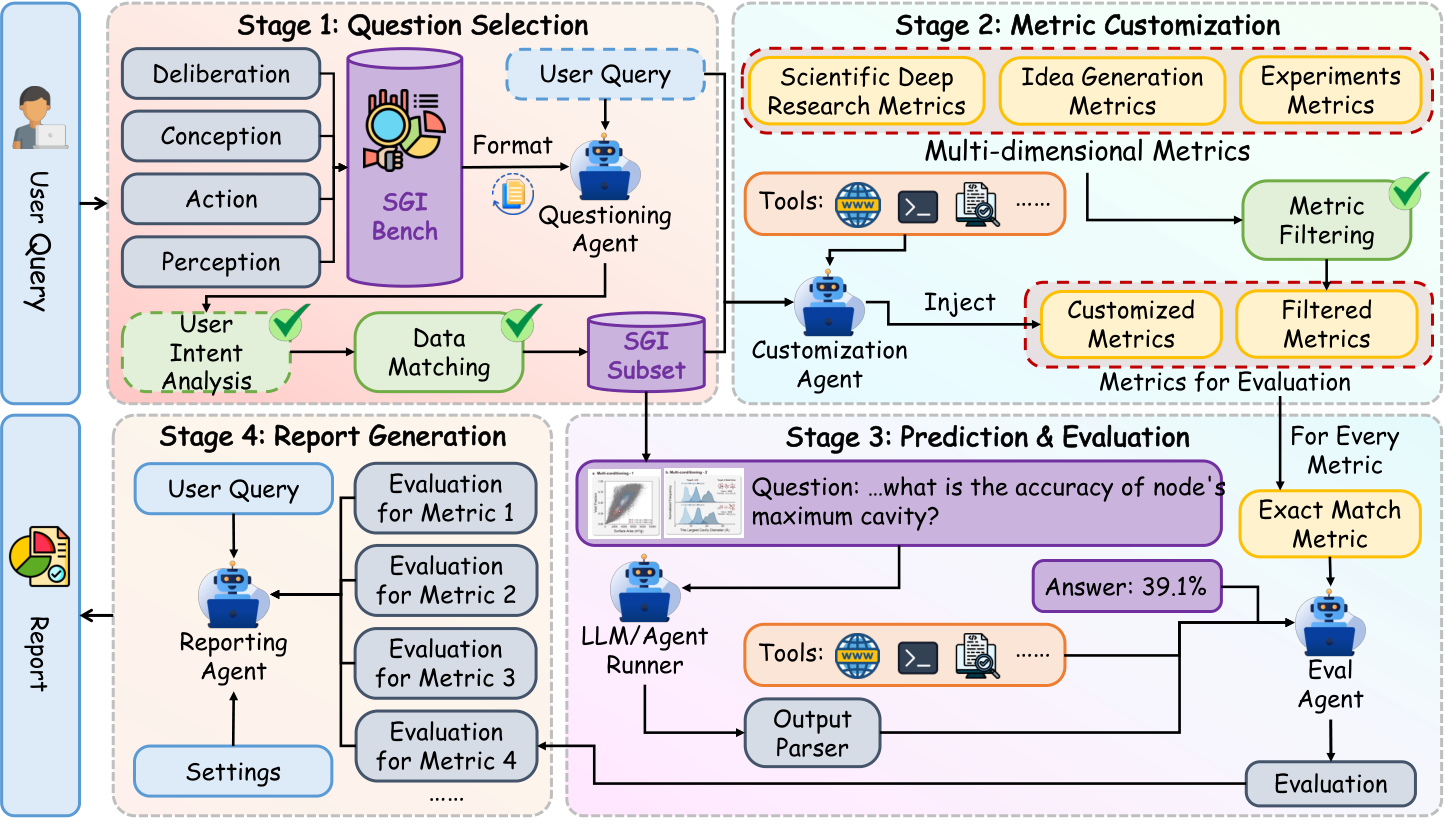
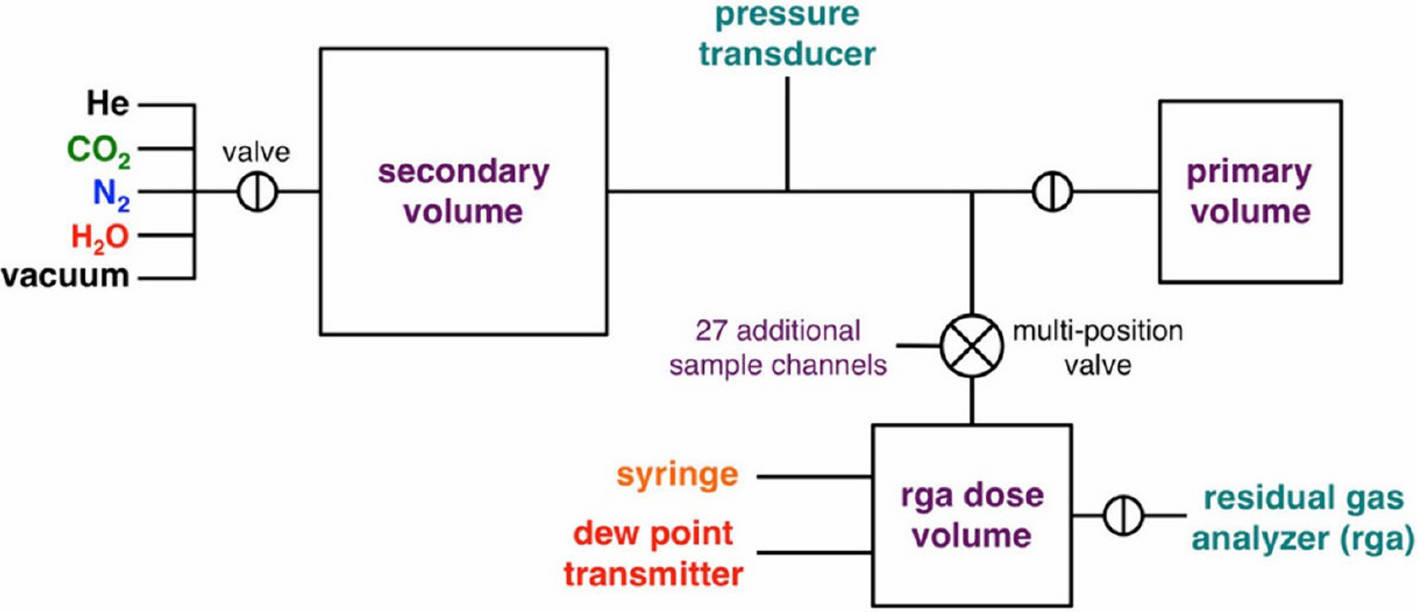
Question Selection → Metric Customization → Predict & Eval → Report Generation.
Web search, PDF parser, Python interpreter, file reader, metric functions.
EM/SLA; Implementation Similarity; PassAll@k/SER; MCA/RV.
Add scientist-aligned metrics (e.g., rigor, feasibility) on demand.
An agent-based evaluation stack coordinating specialized agents and tools to assess models end-to-end with task-specific and customizable metrics. By formalizing question selection, metric construction, scoring, and reporting into traceable stages, it strengthens reproducibility and offers scientist-aligned, actionable insights.
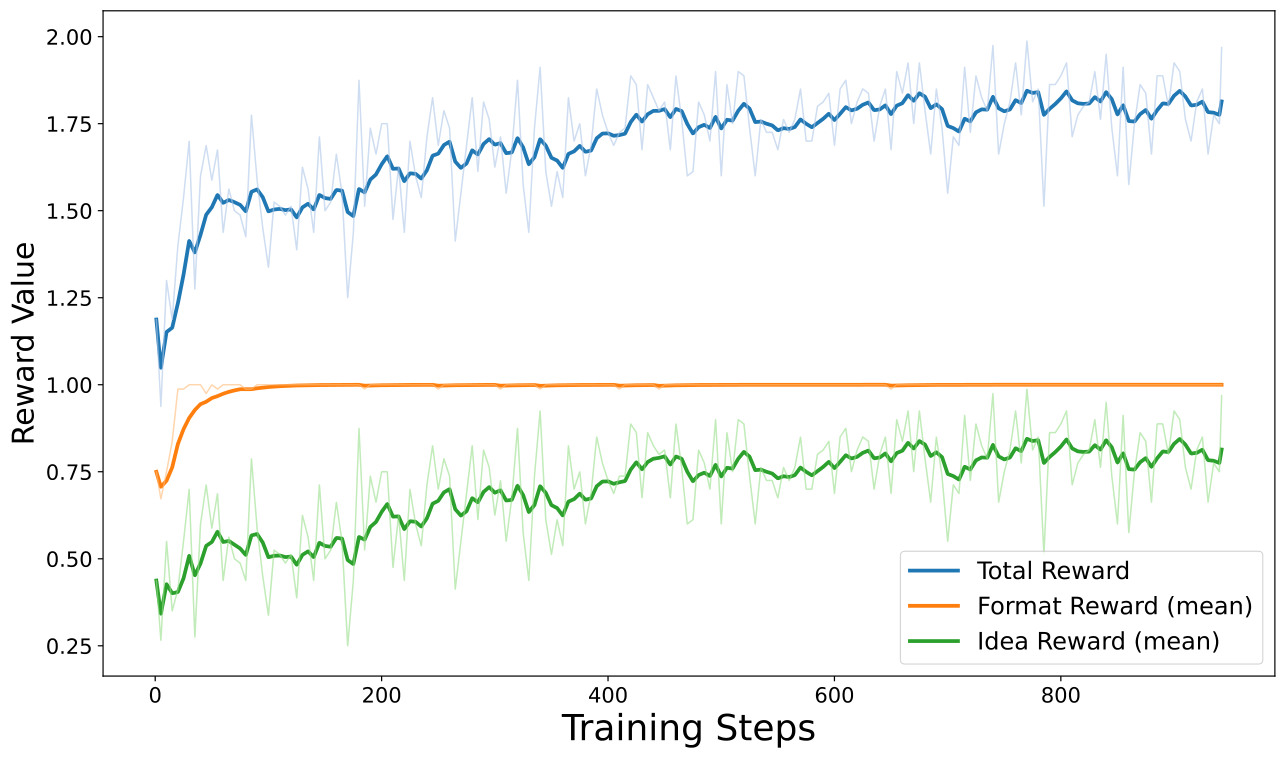
Handle no-ground-truth idea generation by optimizing novelty at test time with online retrieval as baseline.
R = R_format + R_novelty. Enforce XML format; reward embedding dissimilarity from retrieved works.
GRPO on Qwen3-8B (ms-swift); group sampling G=8, high temperature, bfloat16.
Format reward saturates quickly; novelty improves from 49.36 → 62.06 without labels.
TTRL converts open-ended scientific exploration into a measurable test-time optimization process. It improves idea novelty without labels by coupling strict output structure with retrieval-grounded rewards, and generalizes to multi-objective optimization balancing creativity with rigor and feasibility.
Watch how the agentic evaluation framework assesses models through question selection, metric customization, prediction, and reporting.
Explore scientific multimodal inputs across process, observation, experiment, simulation, and visualization images.

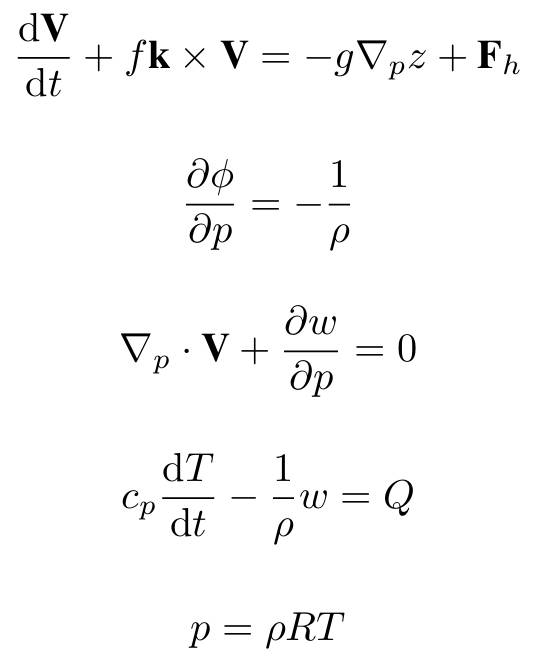
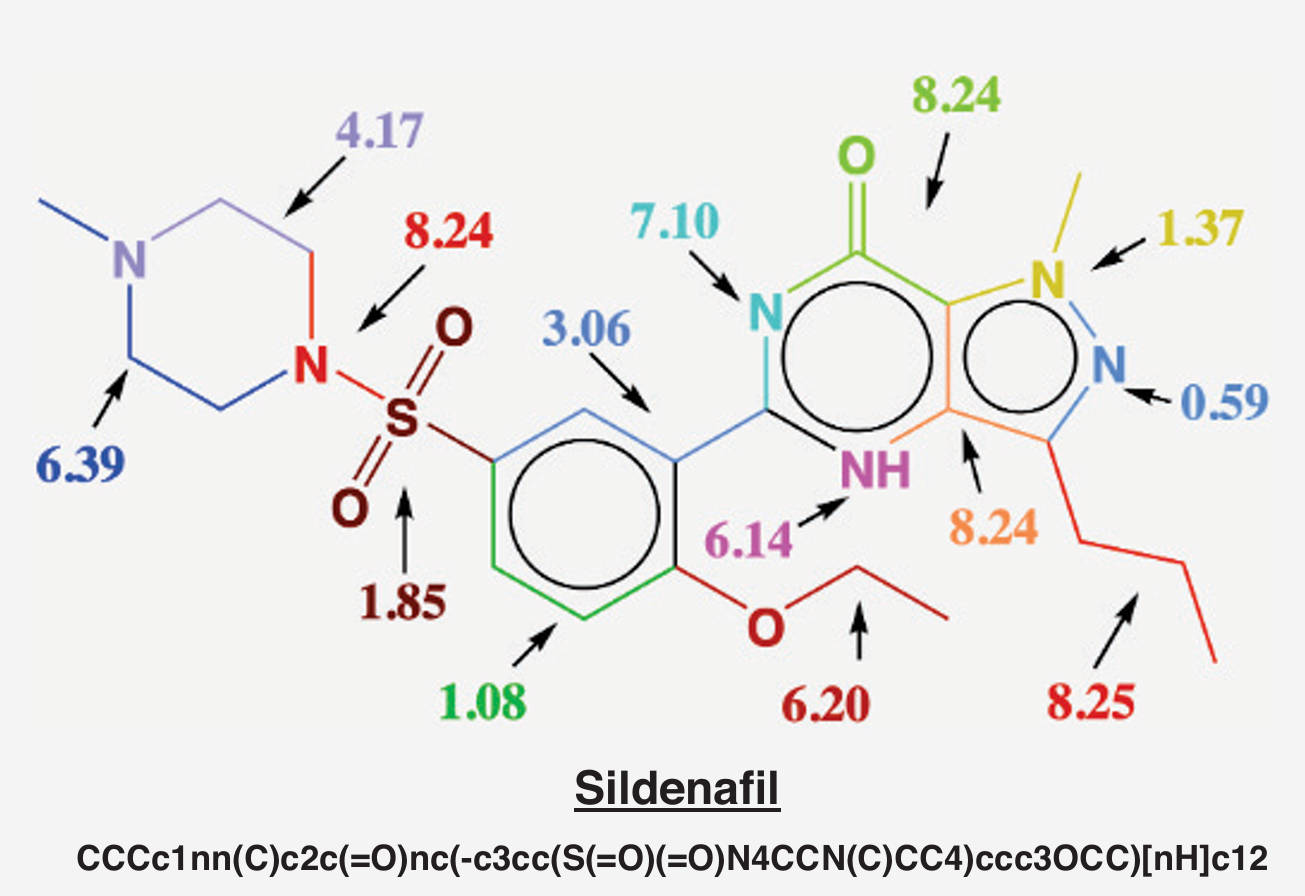
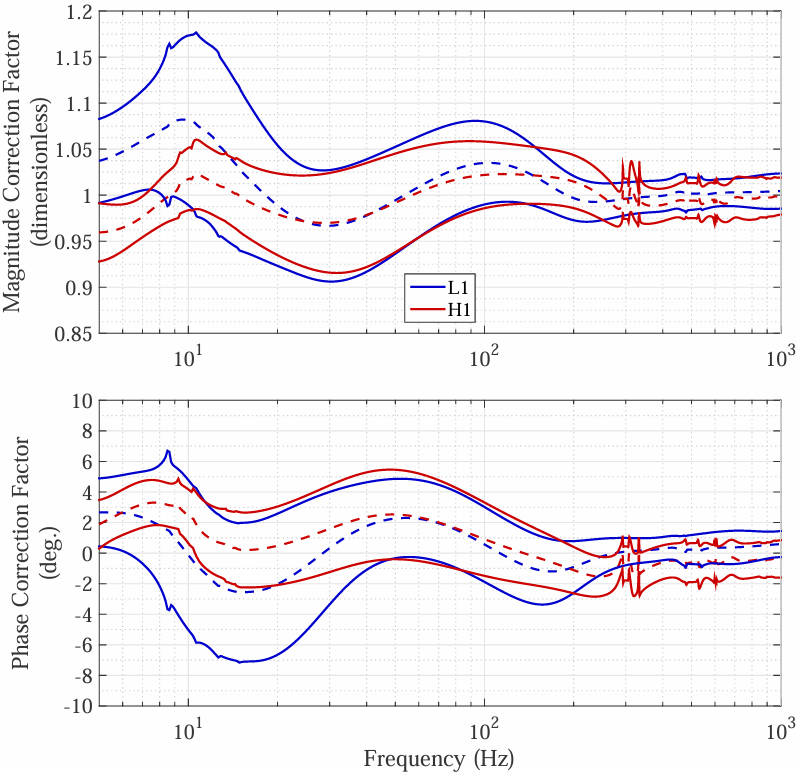
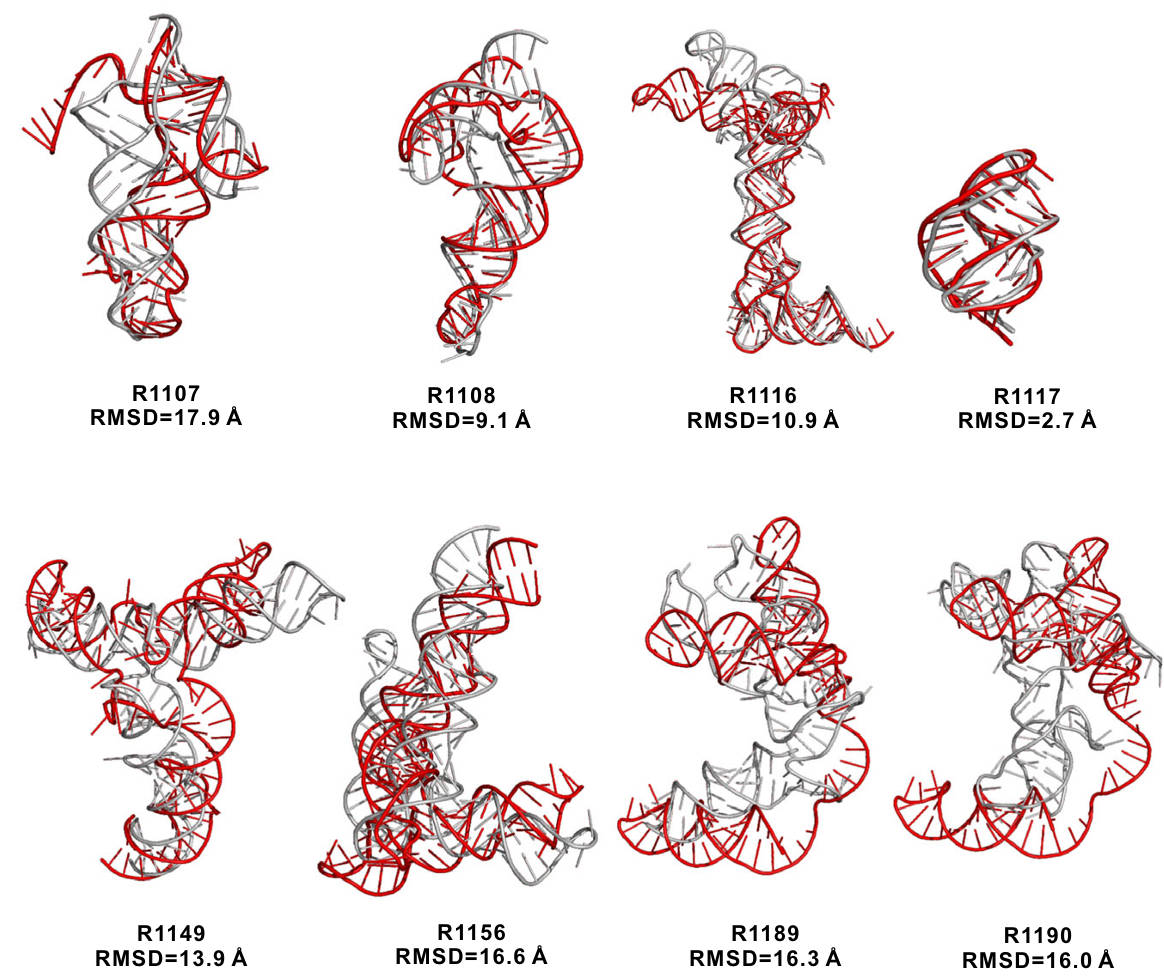

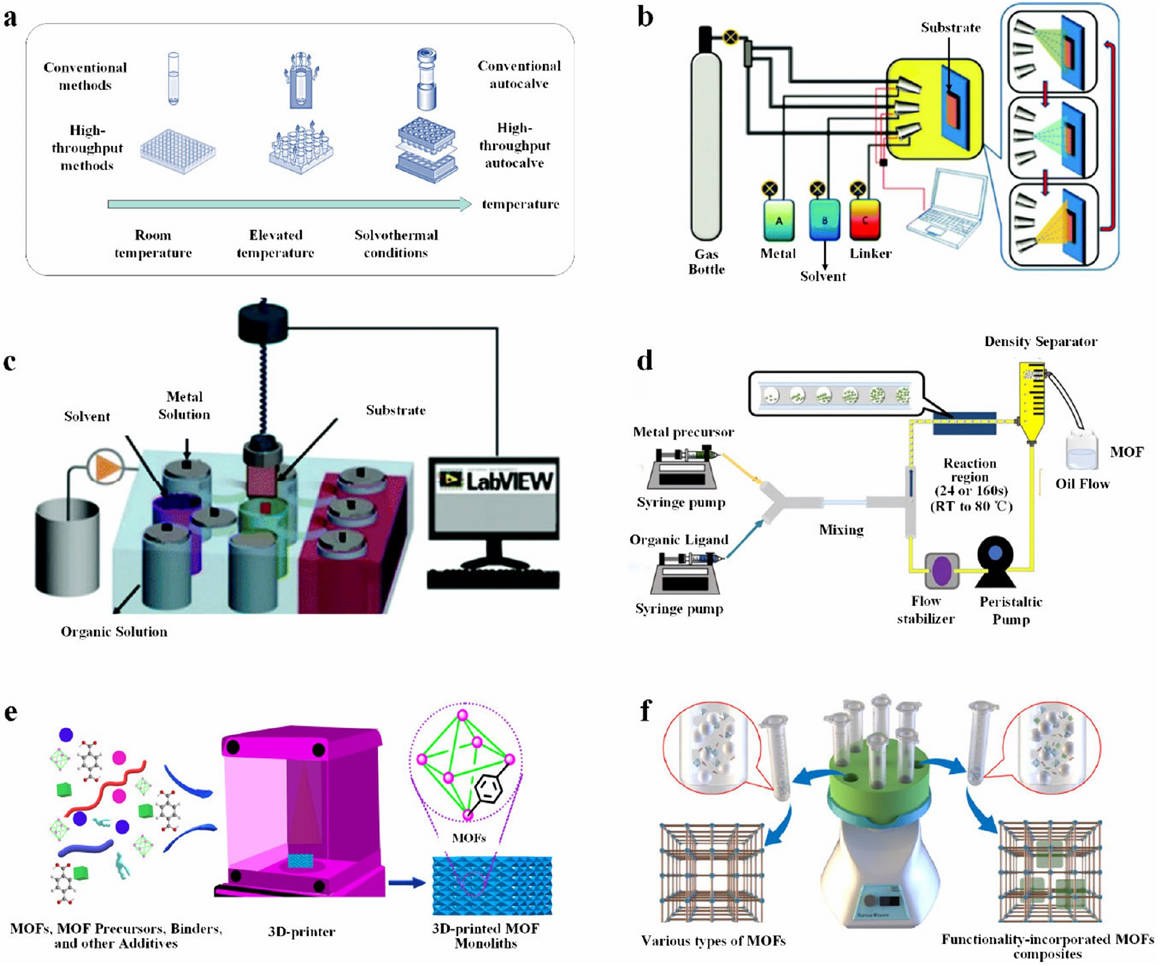

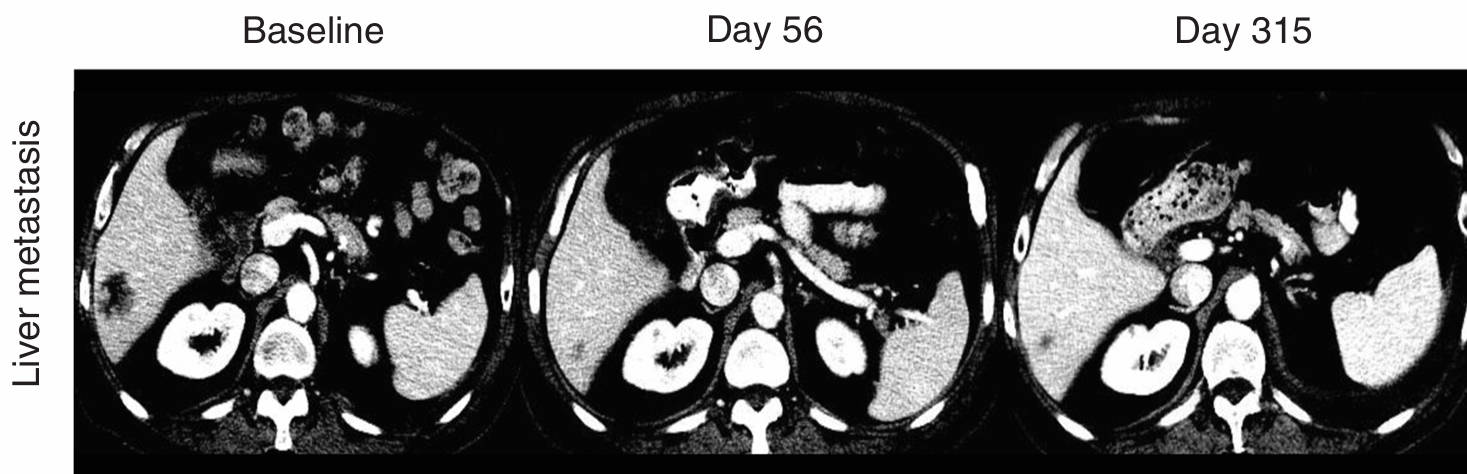
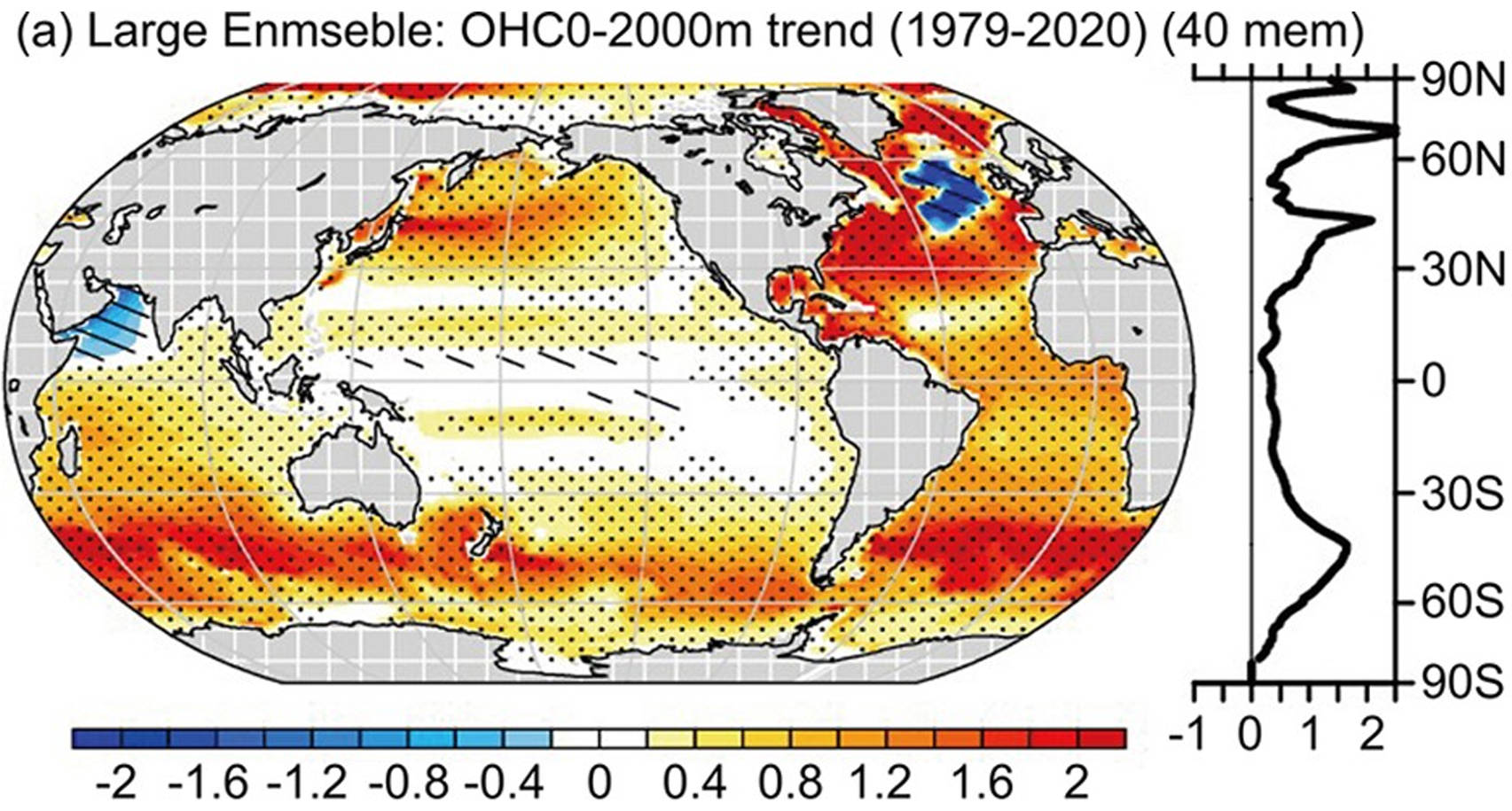
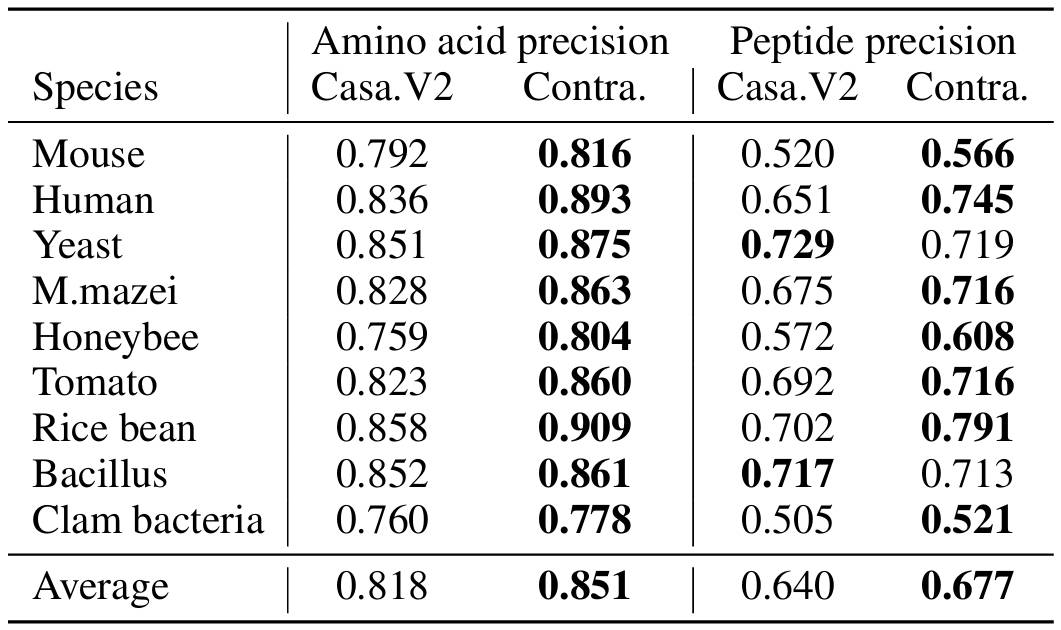

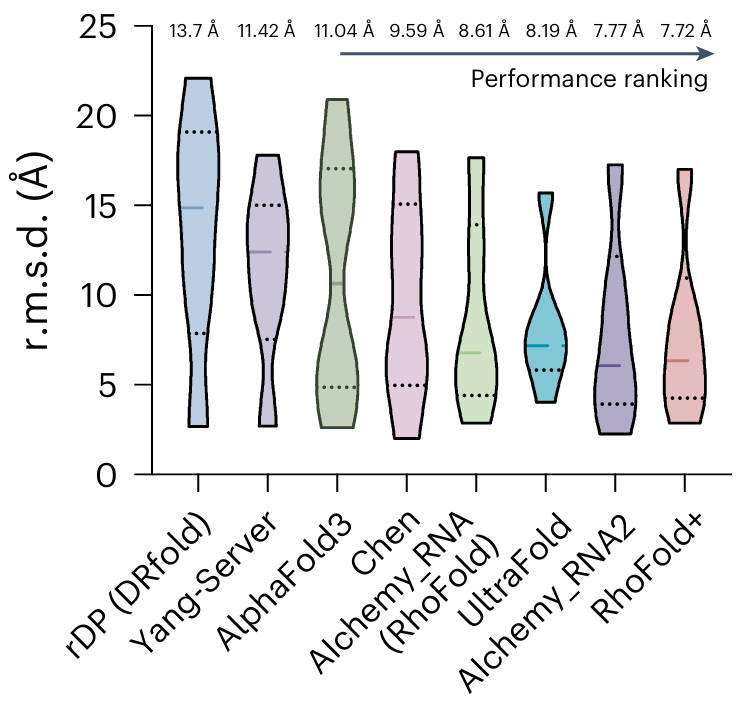





Comprehensive evaluation across five task families spanning 10 scientific disciplines.
| Model | Type | Deep Research | Idea Generation | Dry Experiment | Wet Experiment | Exp. Reasoning | SGI-Score |
|---|
Overview: Deep Research uses Exact Match; Idea Generation uses four-metric average; Dry Experiment uses PassAll@5; Wet Experiment averages Action Sequence Similarity and Parameter Accuracy; Experimental Reasoning uses Multi-choice Accuracy. SGI-Score is the mean across all tasks.

| Model | Type | Exact Match | Step-Level Accuracy |
|---|
Analysis: Models show step-level alignment (SLA up to ~65%) but low exact-match accuracy (10-20%), with brittleness in cross-paper numeric aggregation and mechanism synthesis.
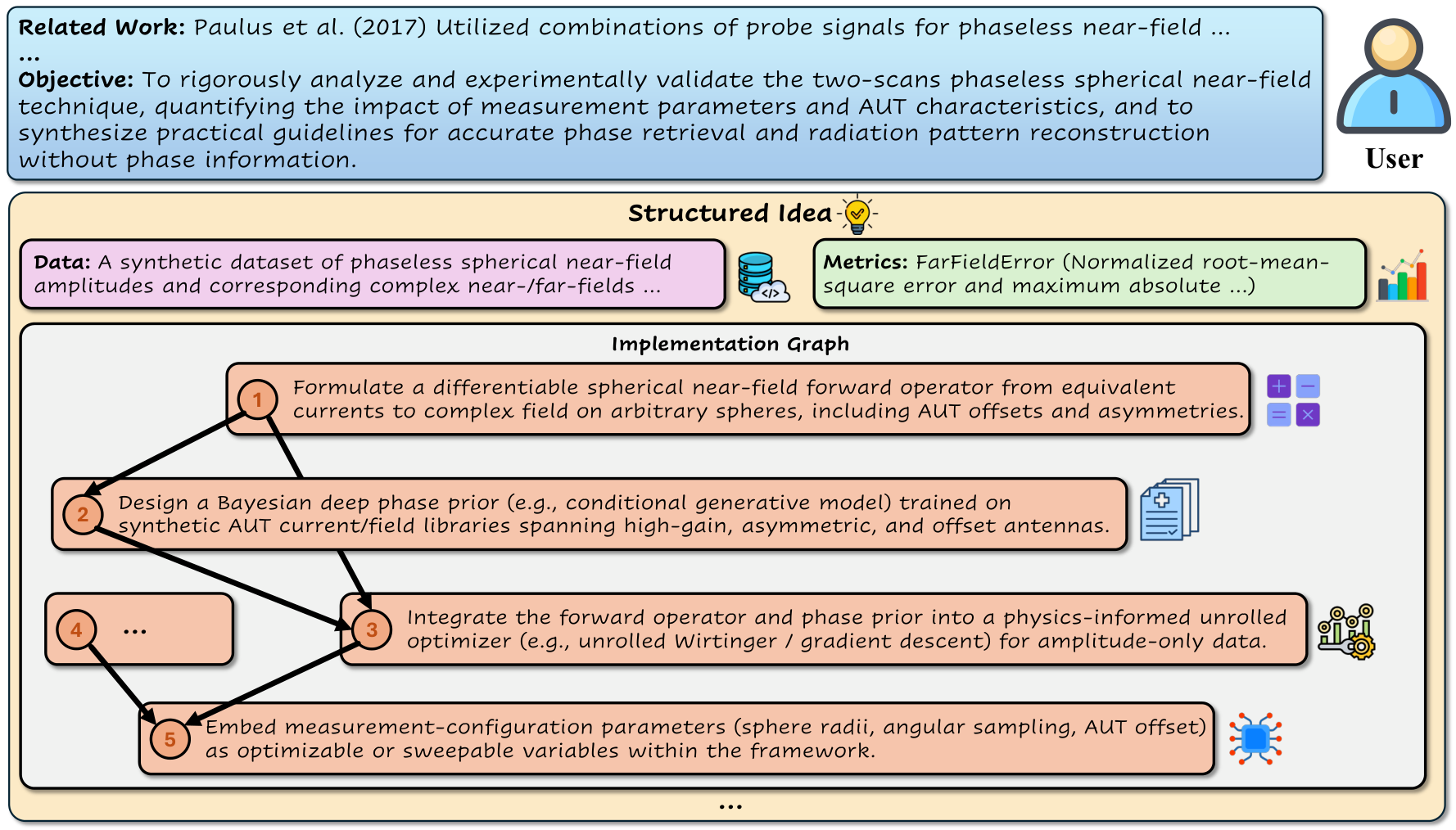
| Model | Type | Effectiveness | Novelty | Detailedness | Feasibility | Average |
|---|
Analysis: Models show high Novelty but Effectiveness is moderate and Feasibility remains low. Even top models with detailed ideas struggle to produce practical plans.

| Model | Type | PassAll@5 | PassAll@3 | PassAll@1 | AET (s) | SER |
|---|
Analysis: Most models generate syntactically valid, runnable code (SER >90%) but show low test-case correctness (PassAll@5 ~36.64% best), exposing that code fluency does not imply scientific computational competence.
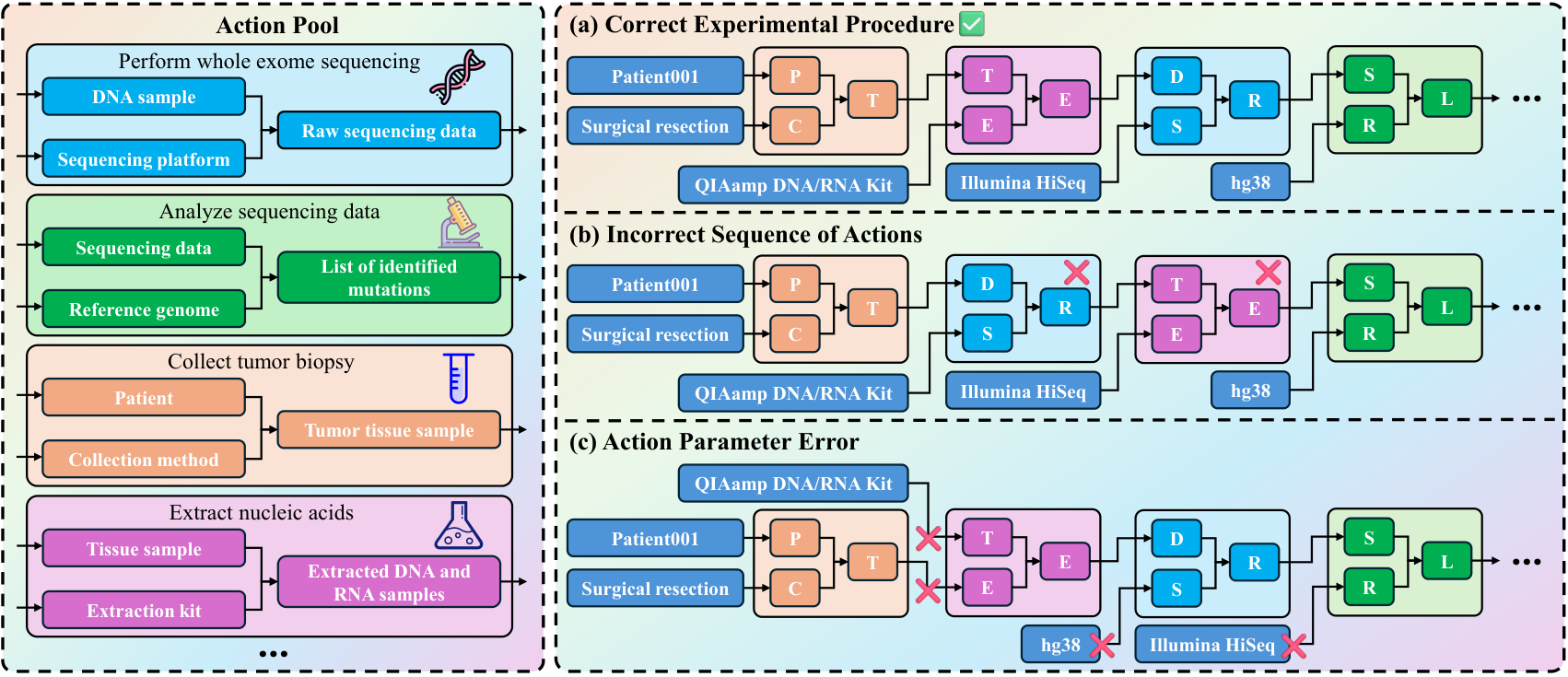
| Model | Type | Action Seq. Similarity | Parameter Accuracy | Average |
|---|
Analysis: LLMs can list reasonable lab actions but fail to organize them into correct experimental trajectories, showing low sequence similarity and parameter accuracy.
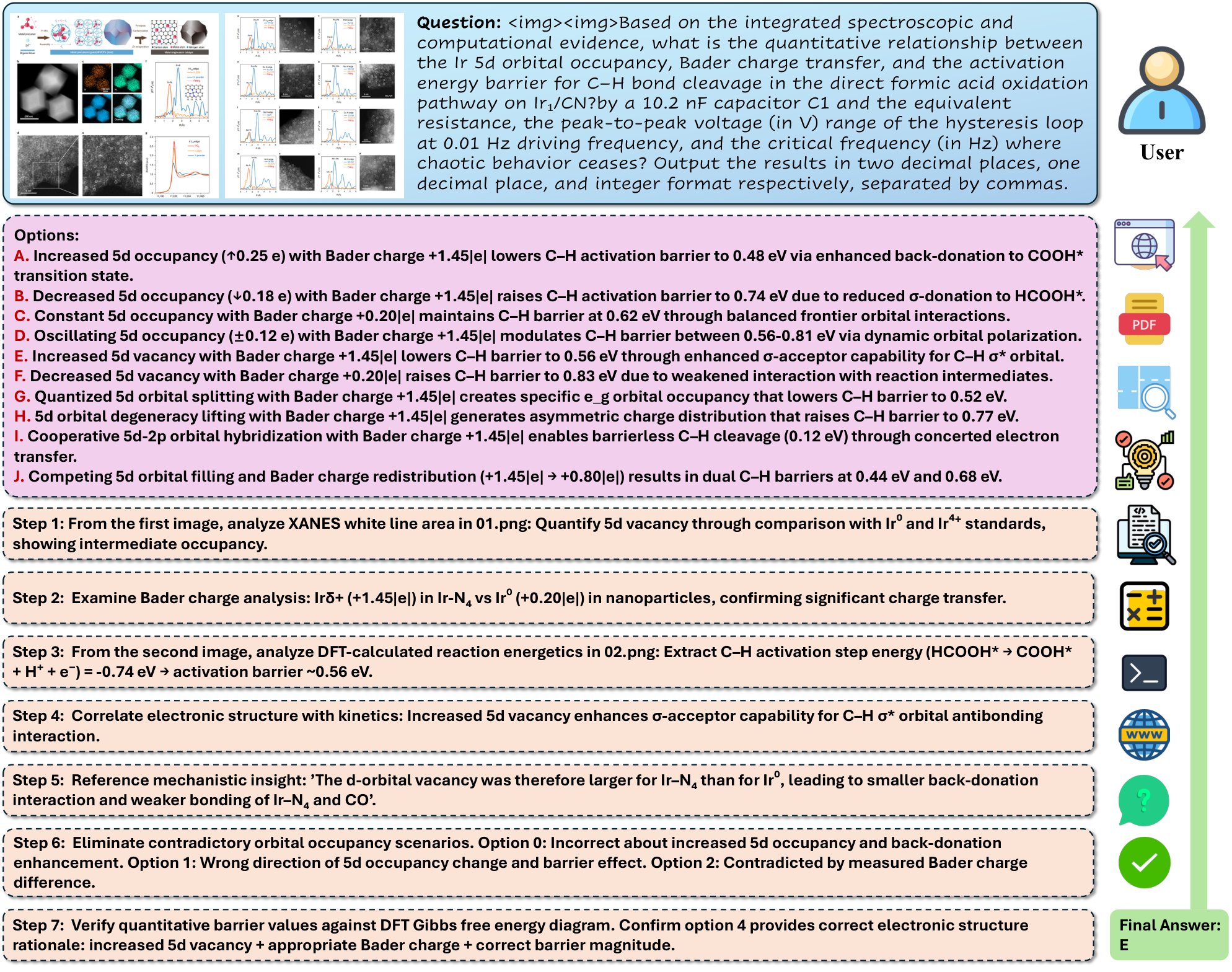
| Model | Type | Multi-choice Accuracy | Reasoning Validity |
|---|
Analysis: Open-source models substantially lag behind closed ones in Multi-choice Accuracy, but most LLMs produce better Reasoning Validity than answer accuracy, revealing persistent bottlenecks in comparative reasoning and numeric extraction.
This work advances the study of Scientific General Intelligence (SGI) from both theory and practice. Grounded in the Practical Inquiry Model, we formalize SGI as the capacity to navigate the iterative cycle of Deliberation, Conception, Action, and Perception with the versatility of a human scientist. Building on this definition, we operationalize SGI through SGI-Bench, a comprehensive, scientist-aligned benchmark that instantiates four core task families: Scientific Deep Research, Idea Generation, Dry/Wet Experiment, and Experimental Reasoning.
Experiments reveal a consistent pattern: in Deep Research, models show step-level alignment but low exact-match accuracy (10-20%); in Idea Generation, hypotheses are fluent but underspecified and infeasible; in Dry Experiment, code is executable but PassAll@k remains low; in Wet Experiment, sequences show omissions and misordering; and in Experimental Reasoning, causal reasoning outperforms comparative, with persistent multimodal challenges.
Taken together, SGI-Bench clarifies both what SGI is and where current systems fail. By integrating principled task design, multi-metric evaluation, and agentic tool use, our framework provides a concrete foundation for systematically advancing SGI. The combination of numerically robust reasoning, planning-aware conception, executable experimentation, comparative multimodal inference, and dynamic test-time learning charts a clear path toward general intelligence systems capable of genuine scientific discovery.
@article{xu2025probing,
title={Probing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows},
author={Xu, Wanghan and Zhou, Yuhao and Zhou, Yifan and Cao, Qinglong and Li, Shuo and Bu, Jia and Liu, Bo and Chen, Yixin and He, Xuming and Zhao, Xiangyu and others},
journal={arXiv preprint arXiv:2512.16969},
year={2025}
}